IO Model
|
I / O 模型
I / O 模型的概念大概有:阻塞 / 非阻塞 / 同步 / 异步
1 | 一个用户进程发起 I/O 请求的例子: |
阻塞 vs 非阻塞
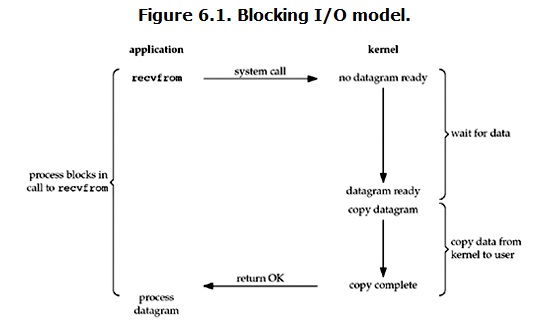
阻塞 ( Blocking IO ):用户发起 I/O 操作后,需要等待其操作完成之后才能继续运行
- 特点:阻塞式 I/O 模型简单。易于理解,但性能差,会照成用户 CPU 大量闲置
- 优化:可以采用多线程的方式进行请求调用,但并不能解决根本问题
非阻塞 ( No-Blocking IO ):用户进程发起 I/O 操作后,无需等待操作完成,会直接返回调用结果,即如果数据没有准备好,会直接返回失败,这就需要用户进程要定期轮询 I/O 是否就绪
- 特点:能立即得到返回结果,当使用一个线程去处理 socket 请求,可以极大减少线程数量。但用户线程会不断轮询会增加额外的 CPU 的资源开销
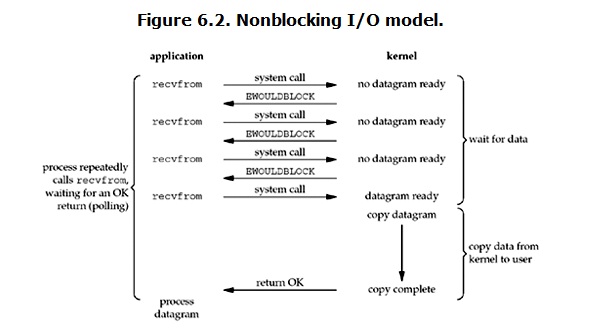
- 总结:阻塞 IO 与 非阻塞 IO 的本质区别主要在于 用户程序是否再等待调用结果(继续等待还是得到结果先处理其他事情)
同步 IO vs 异步 IO
- 同步 IO ( Synchronous IO ) :当系统内核将处理数据操作准备完毕之后,会主动读取内核数据,用户进程需要等待内核将数据复制到用户进程之后,再进行处理
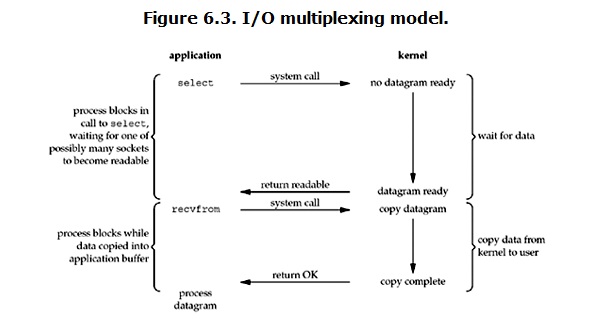
IO 多路复用 ( IO- Multiplexing ):可以监视多个描述符,一旦某个描述符读写操作就绪,就可以通知程序进行相应的读写操作
应用:Linux中使用的 I/O 多路复用机制:select, poll,epoll ( event driven IO),尽管实现的方式不同,但都属于同步 IO,它们都需要在读写事件就绪后,再自己进行读写的操作,内核向用户进程复制数据的过程仍然是阻塞的。
- 特点:尽管使用了事件驱动判断就绪,但与 Blocking-IO 并没有什么太大的不同,甚至在读取的过程中,因为会使用到两个 system call ( select, recvfrom),相比于 blocking-io 的一个 recvfrom,可能在连接数不高的情况下,性能会更差。但有了 select 的优势就在于系统可以同时处理多个 connnection,效率更高。
- 异步 IO ( Asynchronous IO ) : 当用户进程发起 IO 请求后,会直接返回请求成功,等到再接受到内核的 signal 通知的时候, IO 操作已经完成了
非阻塞 ( no-blocking io ) vs 异步io ( asynchronous io )
no-blocking io:虽然大部分时间都不会 block (loop check data ready),但内核数据准备好之后,还是需要主动调用 recvfrom 系统调用进行数据的复制,这期间 process block
asynchronous io:整个过程会将任务交由内核处理,直到 IO done,才会向用户进程发送信号通知成功
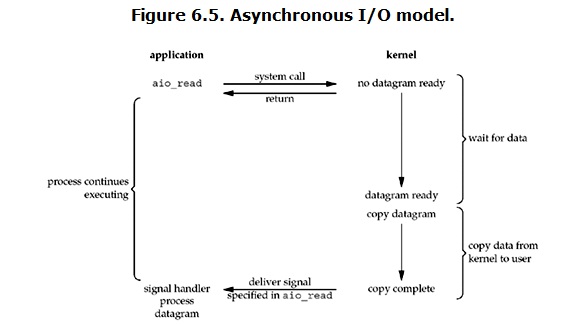
- 总结:同步 IO 和 异步 IO的本质区别在于内核数据 复制到 用户空间的时候用户线程是否阻塞等待
- 大总结
