Zero-Copy
Linux Zero-Copy
什么是零拷贝 ?
Zero Copy 是一种避免 CPU 将数据从一块存储拷贝到另一块存储的技术。 Zero Copy 可以减少数据拷贝和共享总线操作的次数,消除传输数据再存储器之间不必要的拷贝次数,从而有效地提高数据传输地效率。
Linux IO Copy
- read() && write()
当我们在访问一个网页的时候,在 Web Server (Linux) 会调用一下两个 文件读写函数:
1 | read(fd, buffer, len); |
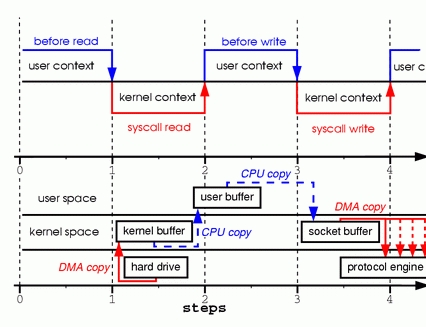
过程分析:
调用 read(),将具体的磁盘文件数据读取到 内核(kernel)的文件系统缓冲区中
接着是将 内核缓存区的数据 拷贝到 用户的缓冲区中
调用 write(),将用户缓冲区的数据写入到 内核 socket 的发送缓存区中
在 write() 返回后,内核会将 socket 发送区的数据拷贝到 网卡驱动中
性能分析:
这个过程中,一共发生了四次 I/O copy, 这期间数据按照 kernel -> user -> kernel -> hard drive 的路线,在 内核 到 用户 白白消耗了一圈的 性能开销,同时除了考虑 I/O 的性能开销,还要考虑系统 context switch 带来的开销,当系统调用 read() 时,系统会从 用户态 切换到 内核态,当 read() 返回时,又需要将 内核态 切换到 用户态,同理,write() 也会导致两次的 context switch,也就是说 read() 和 write() 总共会导致 4次的 I/O copy 和 4次上下文切换。
sendfile()
而采用 sendfile()可减少在 read() & write() 所产生的多次 I/O 拷贝和 context switch
1 | sendfile(sockfd, fd, NULL, len); |
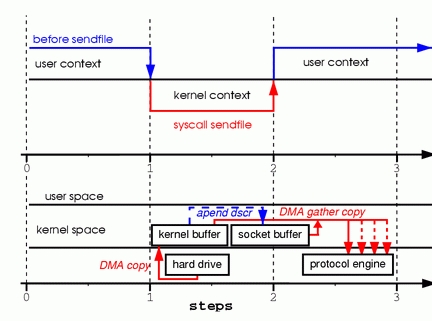
过程分析:
将磁盘中的文件数据拷贝到 内核中的文件缓冲区
向 socket buffer 中 追加 当前的数据在 kernel buffer 中的位置和偏移量
根据 socket buffer 中的位置和偏移量,将 kernel buffer 中的数据 copy 到 网卡驱动中
性能分析:
这次过程中,sendfile() 相比于 read() & write() ,对于将要发送的数据 (socket) ,采用的是记录下对应的 数据在 kernel buffer 中的 位置和偏移量,在最后要发送 socket buffer的数据到网卡设备时,只需通过 位置及偏移量 找到对应 kernel buffer的数据。相比于 read / write, 少了两次 I/O copy,和两次 context switch,性能有了很大的提升。
总结
为什么说是 zero-copy 呢? 因为在 sendfile() 调用的过程中,对于内核 kernel ,整个过程中是零拷贝的,不涉及 内核到用户之间的数据拷贝。