Random
|
Ramdon
伪随机数
在大部分的程序语言中,随机数的生成都是伪随机的。什么是伪随机呢?伪随机性(Pseudorandomness)是指一个过程看起来是随机的,但实际上不是。它通常是使用一个确定性的算法计算出来的似乎是随机的数字,我们只要确定算法计算过程中的初始值,那么计算得到的随机数将会是固定的。
如果要获得真正的随机数,那么仅仅依靠软件去生成随机数是不够的,还需要一些随机的事件得到对应的参数指标,例如在 Linux 中获取随机数的方式就是依靠 intel CPU 电路中的热噪声信号产生的随机数,或者是用户的键盘输入的位置速度,大气中的噪声等方式获取真正的随机数,但都是依赖于专业的设备硬件。
伪随机算法
- 线性同余方法(Linear Congruential Generator)LCG
- 梅森旋转算法(Mersenne twister) MT
- M-sequence(Maximum length sequence) MLS
LCG
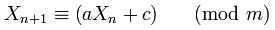
随机数的生成采用了递归公式,这里的 $ X_n $ 表示第 n 个数,$ X_n+1 $ 表示由上一个随机数得到的当前数值,变量 a, c, m 都是常数,LCG 的周期最大为 m,但大部分情况下都会小于 m,要令 LCG 达到最大周期,需要满足以下条件:
- c,m 互为质数
- m 的所有质因数都能被整除 a - 1
- 如果 m 是4的倍数,那么 a - 1 也是
- a, c, n都比 m 小
优点:生成随机数的速度快,消耗内存小,但得知 seed 的情况下,容易根据随机的区间推断出来
MT
梅森旋转算法是基于二进制字段上的矩阵线性递归 $F_2$,对于一个 k 位的长度,MT 会在[0, $2^k$ - 1] 的区间之间生成离散型均匀分布的随机数,由于周期很长($2^10037$ - 1),使得随机数得区间更大,通过对 seed 生成得梅森旋转链进行旋转,处理得到旋转结果,使随机数在区间内均等分布。
因为其优秀得生成随机数速度及内存消耗空间得优化,在多个程序语言中已经使用,如 Python,PHP,Puby等。